

The Ask the SMXpert series continues the question and answer (Q&A) segment held during sessions at Search Marketing Expo (SMX) West 2018.
Today’s Q&A is from the Latest in Advanced Technical SEO session with Dawn Anderson, Bastian Grimm and Brian Weiss, with an introduction from moderator Michelle Robbins.
Michelle Robbins
Technical SEO is the foundation upon which all other SEO efforts are built. Without proper attention to the architecture of a site — in a variety of respects — the best content and marketing efforts in the world will not pay off in the organic SERPs.
We assembled a panel of technical SEO experts for our Search Marketing Expo event to address the critical elements of site speed, site crawling and the technology driving conversational search’s evolution. The speakers’ presentations were loaded with actionable tactics and tips that led to a lively Q&A with the audience. The experts respond to some of those same questions below.
Dawn Anderson
Slide deck: Some Current Challenges with Voice and Conversational Search
Question: Search engines claim to now be able to recognize voices at a level similar to that of human error rate. Does this mean they should be able to answer voice search queries with a similar level of understanding?
Dawn: Even though search engines claim to recognize voices and can answer comprehension questions on Wikipedia pages, this doesn’t automatically mean real natural language “understanding.” There are certainly some challenges still faced in meeting informational needs of users with this technology.
Last summer I was fortunate to attend the biennial European Summer School on Information Retrieval in Barcelona. Lectures were delivered by researchers from leading universities and commercial organizations like Facebook, Bloomberg, Amazon, and importantly, for this topic, Google.
One of the lecturers was Enrique Alfonseca, who is on the conversational search research team at Google Zurich and one of the researchers behind some well-known conversational search and natural language processing papers.
In one of his lectures, Alfonseca talked through a few of the challenges still faced in conversational search. Some of them were quite straightforward and can be converted into simple actions such as:
- Keep sentences and answers short.
- Answer the query or question at the beginning of sentences and paragraphs.
- Avoid tables as they don’t fare well in voice search.
- Check structured data first, fill gaps from the web.
Others were more conceptual in nature and make for interesting discussions.
For example, query refinement is not possible in the same way with voice search as keyboard search. Query refinement means the user is given a set of results which may not be quite a perfect match in the first instance.
A large, less-accurate batch of results is recalled, and the user refines what they are looking for as they go along. The user refines the search and provides feedback by either reformulating their query in response to the result set returned or by browsing and clicking on the results before returning back to search and then reformulating the query.
With voice search, this is not possible. There is generally only one answer, and that’s it. The “berry-picking” or “information-foraging” effect is not simple with voice search. Therefore, it is clear that ranking needs to be improved upon significantly.

Question: What makes voice search a challenge?
Dawn: There are many reasons and areas around voice search that make it challenging.
There are still many challenges with natural language processing, such as the use of pronouns (he, she, they, them, etc.) in spoken conversations. This lack of understanding appears to be particularly problematic for multiturn questions, when the user wants to keep the conversation or questioning going and expects the assistant (device) to remember who each pronoun refers to.
This is known as “anaphora,” and understanding it is known as “anaphoric resolution.” Ambiguity is still a huge problem, and particularly in unstructured text masses. This is still a challenging problem. It’s important to add a structure to pages to disambiguate.

Question: What about paraphrasing in voice search to provide at least one answer “near” to the user’s query?
Dawn: Enrique Alfonseca from Google’s conversational search team explained with voice search there is no “paraphrasing” (reformulating the query spoken by the user) undertaken when retrieving a relevant result.
Only compression of information and extraction from documents is carried out when retrieving results to meet the query. In other areas of information retrieval, queries may go through a whole series of reformulations such as lemmatization (reduction to a root form) or stemming (extending a root form to meet same type verbs) or term expansion to include plurals or known synonyms.
Other morphing may include spell correction before query rewriting takes place and even attempts to “paraphrase” a query with the estimated same meaning or summary.
In voice search, precision is more important than recall, it appears. It is better to be accurate and retrieve fewer results (or none) than to recall a near-miss set of several. Expect the user to then filter through the results. Indeed, with 10 blue links and desktop or even small screen options, results diversity could be deemed a positive feature in some cases. Particularly with the more generic informational queries.
For example, “cat” could mean “cat photos,” “cat types” and so forth. With voice search this is not possible; there can be only one, and it needs to be the right one.
In voice search, one could also argue context likely plays a much larger role, and to paraphrase may misinterpret the context of the situation completely.
On the other hand, this difference between assistive and voice search and keyboard-based search may merely be due to this feature being undeveloped to the point of launch “in the wild.” It will be interesting to see whether paraphrasing is added as the technology evolves and data grows.

Bastian Grimm
Slide deck: How fast is fast enough? Next-gen performance optimization — 2018 edition
Question: What’s your recommendation regarding a solid set of metrics beyond the commonly known PageSpeed Insights? There is a broad variety available, from time-to-first-byte, page loaded up to interactivity measurements. What’s really the way to go?
Bastian: Measuring web performance is so much more than just taking a mere look at Google’s PageSpeed Insights Score (PIS). This number simply does not reflect at all how the actual loading process of a website feels like to your user users. Modern websites should utilize the measurement of paint timings and especially pay close attention to the “time to first meaningful paint” event, which marks the point when the most significant above-the-fold layout change has happened and your most important element is visible.
Think YouTube: When you’re visiting that site, what you really care about is the video — this element needs to be there super-fast; elements like navigation, logo, related videos or comments can follow, but the video is your hero element and needs to be there fast!
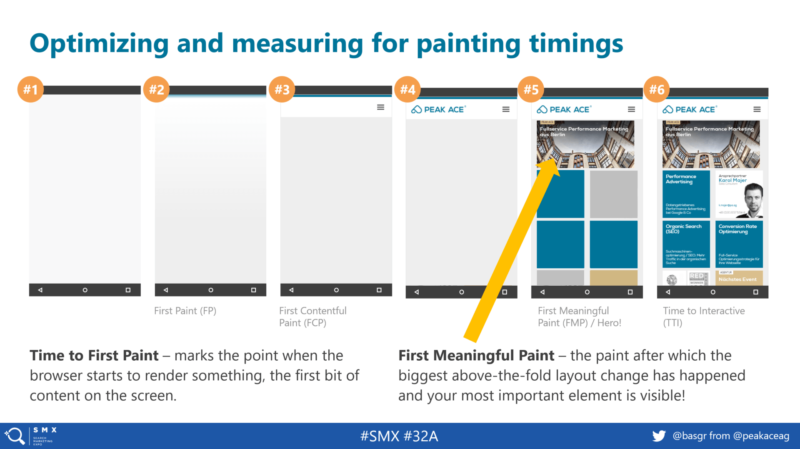 Question: Google is talking about the critical rendering path and above-the-fold content more frequently these days; can you explain the concept around that and why it’s important to them?
Question: Google is talking about the critical rendering path and above-the-fold content more frequently these days; can you explain the concept around that and why it’s important to them?
Bastian: One of the most powerful concepts in web performance optimization is taking special care of your “critical rendering path.” Essentially, this is commonly referred to as the initial view (which is critical for any user since it’s the section of the website they see on their screen straightaway), followed by all contents below the fold (which is not really critical, as you’d have to scroll down to see it).
Making the initial view load very fast has a direct implication on the perceived performance of your website. To do so, you need to get as many render-blocking elements, such as JavaScript or cascading style sheets (CSS), off as possible. Otherwise, the browser will have to wait for each of those files to come back before continuing the render.
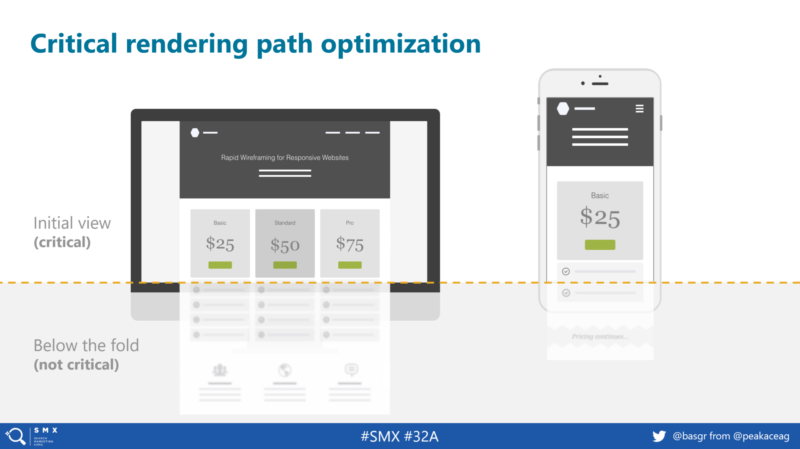 Question: Can you walk us through your routine when it comes to handling CSS? What’s the way to go and get the most out of CSS-specific optimizations?
Question: Can you walk us through your routine when it comes to handling CSS? What’s the way to go and get the most out of CSS-specific optimizations?
Bastian: To speed up your CSS delivery as much as you can, I’d recommend you:
- Launch an audit, clean (de-duplication, get rid of unused styles, etc.) and afterward split your CSS into two parts: one for the “initial view” and rest of the CSS for “below the fold.”
- Use this tool “Critical” (which is free) to help to identify as well as generate the critical required CSS info.
- Inline the previously generated CSS for the initial view (yes, inline!).
- Use rel=“preload“ and “loadCSS” to asynchronously load below-the-fold/sitewide CSS (a noscript tag will provide fallback for clients without JavaScript enabled).
By the way, there is a strong reason why Google is inlining their entire CSS (on their search result pages): It’s way faster than making hypertext transfer protocol (HTTP) requests!

Brian Weiss
Slide deck: Using Crawl Data to Inform Site Architecture. Or, You Can’t Fix What You Can’t Find
Questions: You mentioned getting a “baseline” before crawling and using tools. Why do you need a baseline?
Brian: If you get a baseline understanding of your website BEFORE crawling or using other SEO tools, it will put you in much better position to ask questions and effectively use the data you collect.
Every website has an underlying logic to how pages are created, meta tags are applied and internal links are generated. If through questioning or observation you get an understanding of that logic, then you can extrapolate what the crawl should look like; how many pages of each major type, the percent that should be indexable, etc.
If you get the crawl data back and see something different than what you expected, there are three possible explanations:
- The crawl data is wrong.
- Your interpretation of the site logic was wrong.
- Your interpretation was correct, but you miscalculated the impact it would have at scale.
Any of these three items would be extremely important to know!
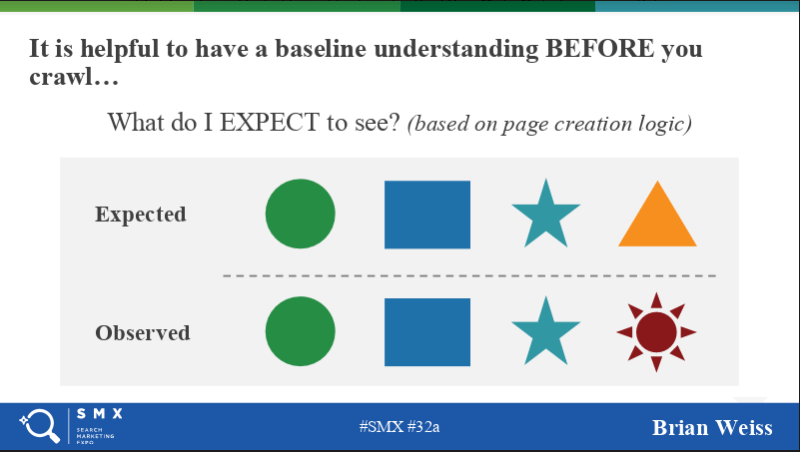 Question: We have pages we don’t want in the index and hear pros and cons of the various methods of keeping them out. What’s your take?
Question: We have pages we don’t want in the index and hear pros and cons of the various methods of keeping them out. What’s your take?
Brian: SEO teams often go to great lengths to make sure they are feeding Google quality pages and content. However, it’s important to remember that the solutions we most often use to prevent indexation of bad pages each has its own cost.
This is especially true on large sites when there start to be more pages that have noindex tags or canonical to another uniform resource locator (URL) than pages that are indexable, which can make it harder for Google to find and crawl all the good pages on the site.
Using robots.txt also has its own cost, as PageRank gets passed to the blocked URLs but can’t flow back into your site. Using nofollow has a similar PageRank impact but is less effective at blocking URLs from crawling — there is rarely a good reason for using nofollow on internal links.
 Question: So is there an approach that doesn’t have the downside associated with the various indexation and crawling controls you mentioned?
Question: So is there an approach that doesn’t have the downside associated with the various indexation and crawling controls you mentioned?
Brian: The non-band aid approach to controlling your quality of pages exposed to Google is simply to not generate links to pages you don’t want indexed.
Of course, this is often easier said than done, and there are always going to be necessary user experiences that don’t make sense for search. When you have these types of pages, some of the best solutions for removing them from your crawl path are:
- Put the pages behind a login.
- Don’t create new URLs — make the changes happen dynamically at the same URL (especially good for sort order changes).
- Don’t pull the URLs into the document object model (DOM) until the user takes an action (such as clicking to expand a menu).

Have a question we didn’t cover?
Do you have more questions for our SMXperts? Complete this form, and we’ll run your question and the SMXpert responses shortly!
[“Source-searchengineland”]
